



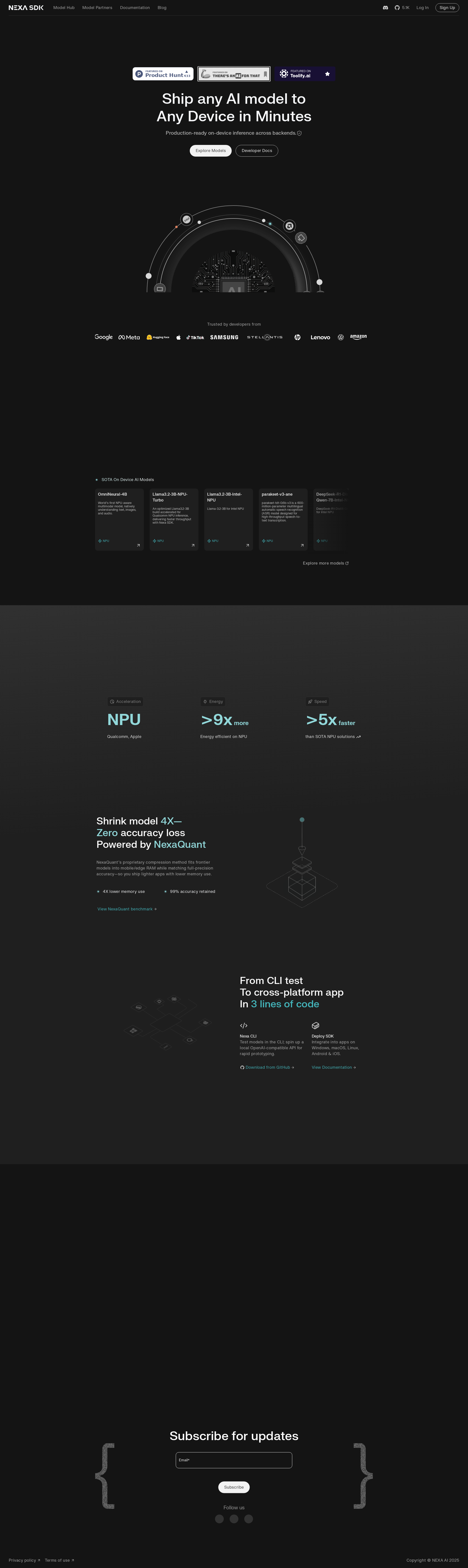
Nexa SDK:在任意设备上快速运行与部署本地 AI 模型
Nexa SDK 官方网站 是一款面向开发者的本地 AI 模型运行与部署工具包,支持在 NPU、GPU 或 CPU 上跨后端运行文本、视觉、音频、语音及图像生成等多种模型。
产品概览
Nexa SDK 旨在帮助开发者快速在本地设备上运行和部署 AI 模型,支持多种硬件后端,包括高通和苹果的 NPU,以及 GGUF、Apple MLX 等格式。它能够处理多种类型的 AI 任务,如文本理解、图像识别、语音转录等,适用于移动设备、边缘计算等场景。
关键能力与特性
Nexa SDK 提供以下核心功能:
多硬件后端支持
- NPU 加速:支持高通和苹果的 NPU,提供高效的推理性能。
- GPU 与 CPU 兼容:可在多种硬件上运行,确保灵活性。
- 统一架构:通过统一架构支持 CPU、GPU 和 NPU,简化开发流程。
模型支持
- 前沿模型:支持最新的 SOTA 模型,如 Gemma3n、PaddleOCR、Llama3.2 等。
- 多模态处理:涵盖文本、视觉、音频、语音和图像生成等多种任务。
- 代理推理:支持如 Jan-v1-4B 等代理推理模型,适用于自动化代理任务。
性能优化
- 能效提升:在 NPU 上运行比现有方案能效高 9 倍以上。
- 速度加速:推理速度比 SOTA NPU 解决方案快 5 倍以上。
- 模型压缩:通过 NexaQuant 技术压缩模型大小至 1/4,几乎无精度损失。
集成与生态
Nexa SDK 提供丰富的集成选项和开发者资源:
- CLI 工具:支持通过命令行测试模型,并启动本地 OpenAI 兼容 API 进行快速原型开发。可从 GitHub 下载。
- 多平台部署:支持 Windows、macOS、Linux、Android 和 iOS 应用集成。详细文档请参考 官方文档。
- 模型中心:提供 模型库 供开发者探索和选择适合的模型。
性能与对比
根据官方数据,Nexa SDK 在 NPU 上的性能表现显著:
- 能效比现有方案高 9 倍以上。
- 推理速度快 5 倍以上。
- 模型压缩技术可减少 4 倍内存使用,同时保持 99% 的精度。
隐私与数据安全
Nexa SDK 专注于本地推理,所有模型运行在设备上,无需云端传输,增强了数据隐私和安全性。具体数据安全细节由开发者官方声明,可能随版本变化,建议参考 隐私政策 和 使用条款。
典型落地场景与上手路径
Nexa SDK 适用于多种场景:
- 移动应用:在智能手机上运行 AI 模型,如语音识别或图像处理。
- 边缘设备:在 IoT 设备或嵌入式系统中部署轻量级模型。
- 快速原型:通过 CLI 和本地 API 加速 AI 项目的开发与测试。
上手路径:
小结与行动建议
Nexa SDK 是一个强大的工具,用于在本地设备上高效运行和部署 AI 模型。它支持多种硬件和模型类型,适合开发者构建隐私优先、高性能的 AI 应用。如需了解更多或开始使用,请访问 官方网站 或查看 文档。
评论区