



nanochat:百元预算的最佳 ChatGPT 替代方案
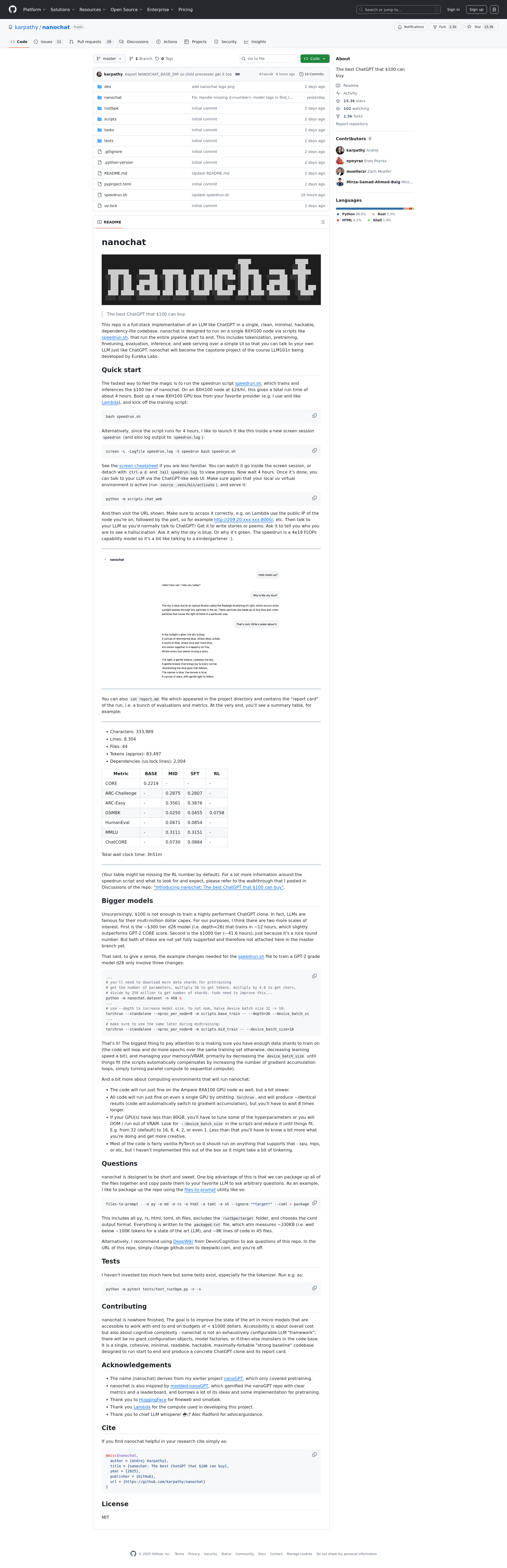
nanochat 官方网站 是一个全栈实现的大语言模型项目,旨在以单一、简洁、最小化、可修改且依赖轻量的代码库,复现类似 ChatGPT 的功能。该项目支持在单个 8XH100 节点上运行分词、预训练、微调、评估、推理及 Web UI 交互的全流程。
产品概览
nanochat 由知名 AI 研究者 Andrej Karpathy 开发,专注于为开发者和研究者提供一个端到端的大语言模型训练与部署方案。其核心目标是降低 LLM 的开发门槛,通过精简的代码结构和明确的执行脚本,让用户能够在有限预算内(如 100 美元)构建属于自己的对话 AI 系统。
关键能力与特性
全流程覆盖
nanochat 集成了 LLM 开发的所有关键环节:
- 分词处理:基于 Rust 实现的高效分词器(rustbpe)。
- 预训练与微调:支持从基础预训练(BASE)到监督微调(SFT)的全阶段训练。
- 评估与推理:内置多维度评估指标(如 CORE、ARC、GSM8K 等),并提供类 ChatGPT 的 Web 交互界面。
- 依赖轻量化:整个项目仅需约 2000 行依赖项(uv.lock),代码库总规模约 8.3 万行代码。
经济高效的训练方案
项目提供 speedrun.sh 脚本,可在约 4 小时内完成 100 美元预算的模型训练(使用 8XH100 节点,每小时成本约 24 美元)。训练完成后,用户可通过 Web UI 直接与模型对话,体验类似 ChatGPT 的交互功能。
性能基准
根据官方测试报告,100 美元级模型在多项基准测试中表现如下:
- CORE 得分:0.2219
- ARC-Challenge:0.2807(SFT 阶段)
- GSM8K:0.0758(RL 阶段)
- HumanEval:0.0854
- MMLU:0.3151
快速上手
运行速度脚本
通过以下命令启动全流程训练:
bash speedrun.sh
建议在 screen 会话中运行以便后台监控:
screen -L -Logfile speedrun.log -S speedrun bash speedrun.sh
启动 Web 交互界面
训练完成后,激活虚拟环境并启动服务:
source .venv/bin/activate
python -m scripts.chat_web
访问终端显示的 URL(如 http://[IP]:8000)即可与模型对话。
扩展与大模型支持
除 100 美元级模型外,项目还计划支持更大规模的模型:
- 300 美元级(d26 模型):约 12 小时训练时间,性能接近 GPT-2 CORE 水平。
- 1000 美元级:约 41.6 小时训练时间,为更高性能需求设计。
用户可通过调整 speedrun.sh 中的参数(如 --depth=26 和 --device_batch_size=16)来适配更大模型训练。
开发环境适配
- 硬件支持:原生适配 8XH100/A100 GPU 节点,单 GPU 也可运行(通过梯度累积模拟多卡并行)。
- 内存优化:若 VRAM 不足,可降低
device_batch_size(如 32→16)以避免 OOM。 - 框架兼容性:基于 PyTorch 实现,理论上支持 xpu、mps 等后端,但需自行适配。
生态与资源
- 代码审查工具:推荐使用 files-to-prompt 或 DeepWiki 分析代码结构。
- 测试套件:包含分词器等组件的单元测试(运行
pytest tests/test_rustbpe.py)。 - 社区支持:项目讨论区提供详细指南(Introducing nanochat)。
隐私与数据安全
本项目为开源代码库,不涉及用户数据收集或处理。所有训练与推理过程均在用户本地环境中完成,无需对外传输数据。
典型使用场景
- 教育与研究:适合高校和研究机构用于 LLM 教学与实验。
- 轻量级部署:中小企业可基于此构建定制化对话系统。
- 开发者学习:通过精简代码理解 LLM 全流程技术细节。
小结与行动建议
nanochat 以“百元级 ChatGPT”为定位,降低了 LLM 开发的经济与技术门槛。其全栈集成、代码精简和明确的工作流设计,使其成为学习和实践大语言模型的理想起点。
- 了解更多:访问 项目 GitHub 查看代码与文档。
- 快速体验:按 speedrun.sh 脚本启动训练。
- 参与贡献:项目欢迎社区协作,共同推进轻量级 LLM 发展。
评论区